


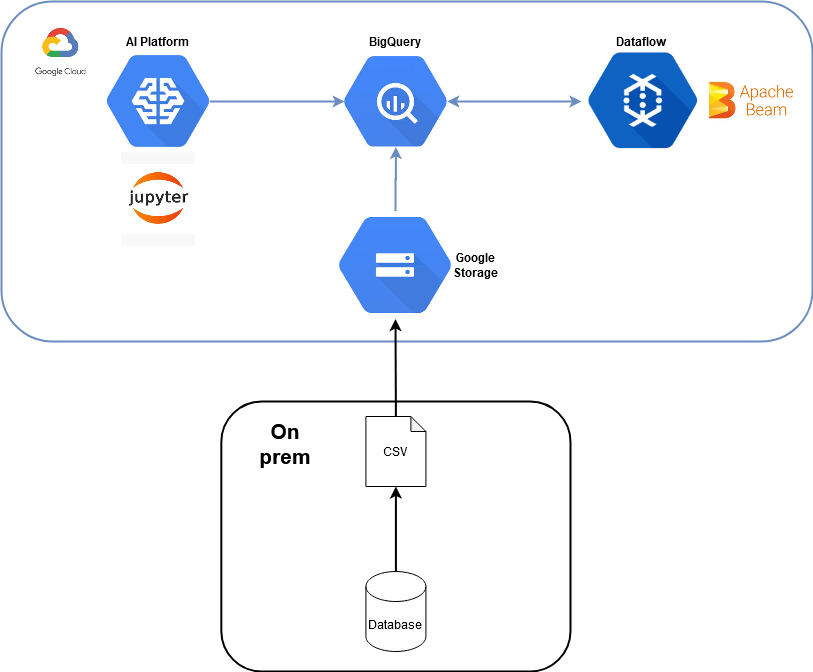
Over the past few months we have been working with improving data insights and innovation. We have achieved this by copying data from on prem systems to a new data platform on GCP.
The easy-to-use, and powerful tooling in the GCP Data Platform have proven valuable in setting up a complete data pipeline; going from an empty sheet to a functional machine learning (ML) setup proved to be both speedy and cost-effective.
In this series of articles, I will show how we can take data from an on prem system in a one time export, load it into GCP, and begin working with ML using the tools available.
The steps we will cover are:
- Data extraction- Making data accessible and available
- Data exploration and cleaning — Making data clean and usable
- Modelling — Making predictions
In the first step, we export data from a database to a file, and loaded it into Google BigQuery using Google Storage. This first and crucial step made the data easily accessible and available for anyone in the organization who wants to work on it. After this, we are ready to start experimenting with the data.
Second, we can use Googles AI Platform to host Jupyter Notebooks for data exploration. This step provides data scientists with an environment where they can iteratively explore and analyze the raw data. It allows for an exploratory process where we can get to know, and identify any issues with our data. When we have gotten to know our data, we will use Google Dataflow, an Apache Beam runtime, to create a cleaned version of our dataset.
Third, we will use Googles AutoML offering called BigQueryML and its Transform clauses for feature engineering, feature selection and modelling. BigQueryML provides an automated process for training and hyper parameter tuning of models, drastically cutting the time necessary for model development. I will also demonstrate how you can embed feature engineering and section with BigQuery ML using transform clauses and XGboost for regression.
Finally, we will complete the most important step and validate the prediction that our model makes.
Making data available and accessible
To make things more interesting we will use a datasets containing trade data of the cryptocurrency Bitcoin. We will use this data with the goal of predicting the future price of Bitcoin.
The dataset contains the open, close, high, low and volume of trade of Bitcoin on Coin base from 2015–08–01 to 2020–10–21
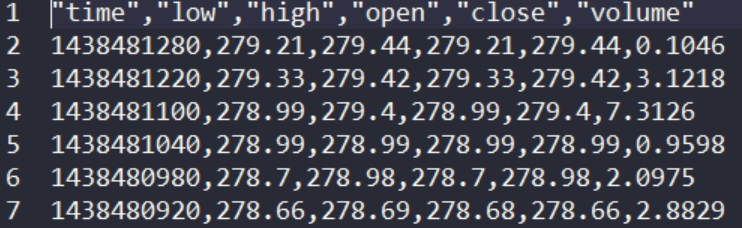
The easiest way to get started working with data on GCP is simply to store your dataset in a Google Storage bucket. Google Storage is an object store which allows for unlimited and cheap storage on GCP. You can refer to the official tutorials for instructions on how to create your buckets.
If you would like to code along, you can access the data in our public bucket here.
BigQuery is a fully managed big data storage service offered by Google on GCP. It allows extremely larga datasets to be stored and accessed by very many concurrent users. It auto scales beneath the surface, removing some of the headaches normally associated with managing Big Data such as managing and scaling infrastructure or IAM. Just load the data and you’re ready to go.
Side note: when talking about Big Data one usually talks about petabytes or exabytes of data. Don’t let that discourage you, we have found that BigQuery also works great as a feature store for AI/ML applications, even for medium, or small data.
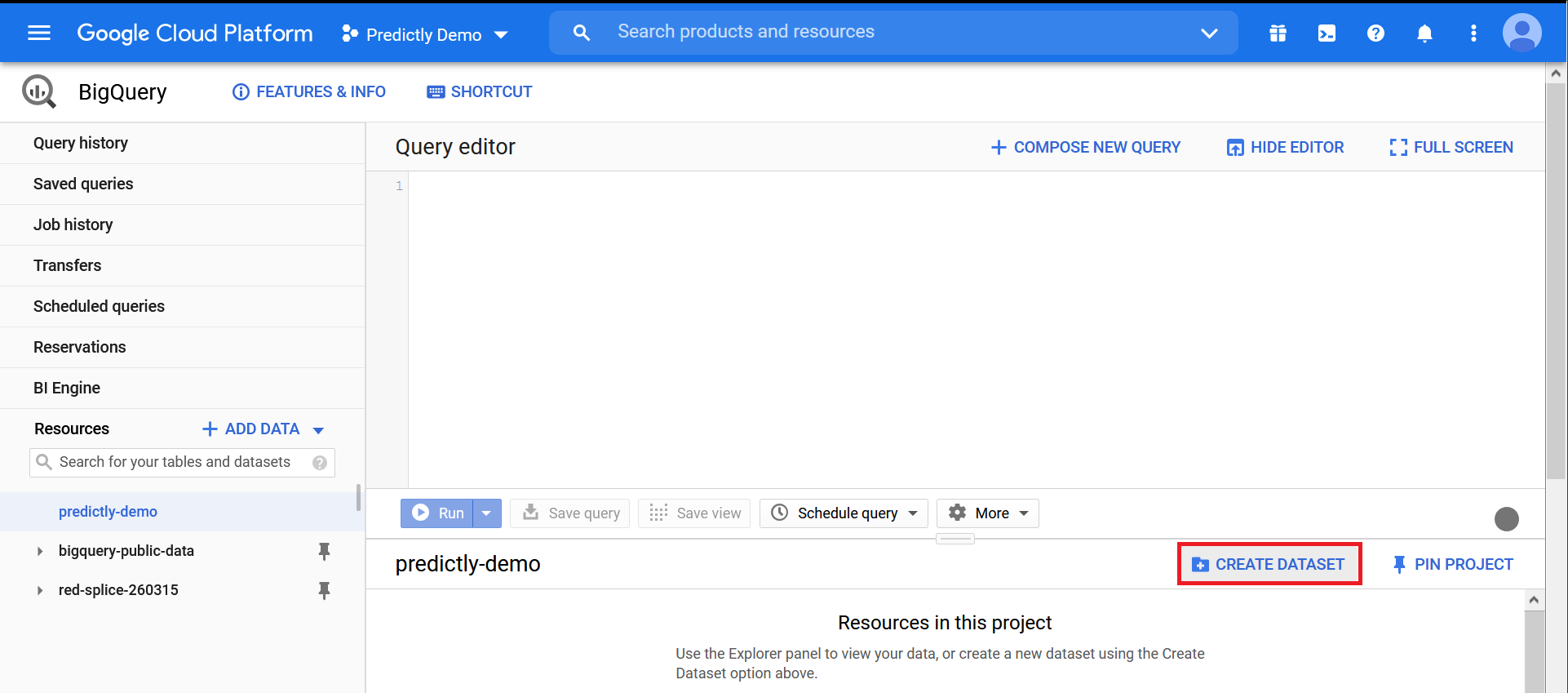
Click the “Create Dataset” button , give your dataset a nifty name. I keep all settings as default for this demo.
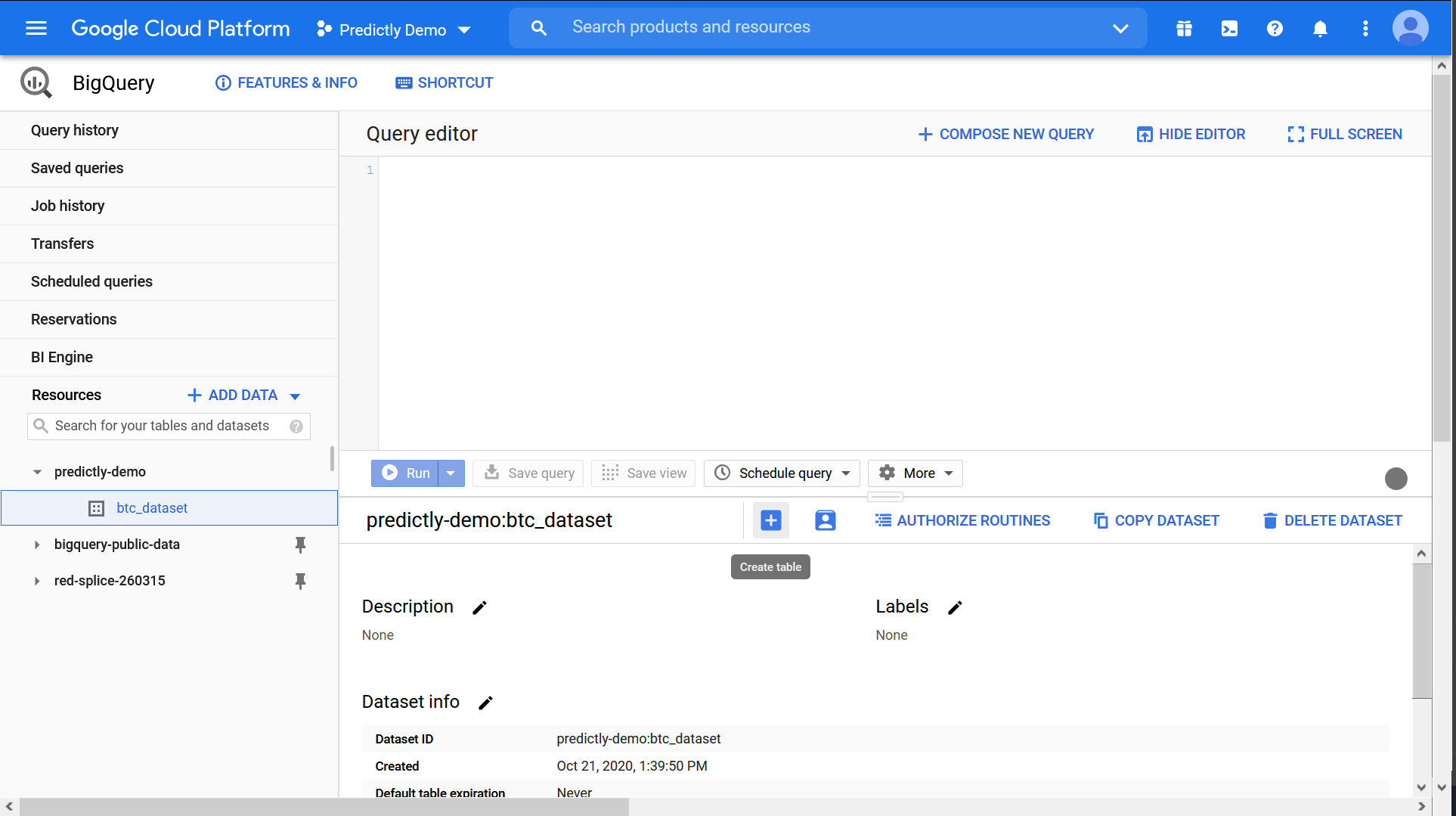
When the dataset is created select it, and click Create table.
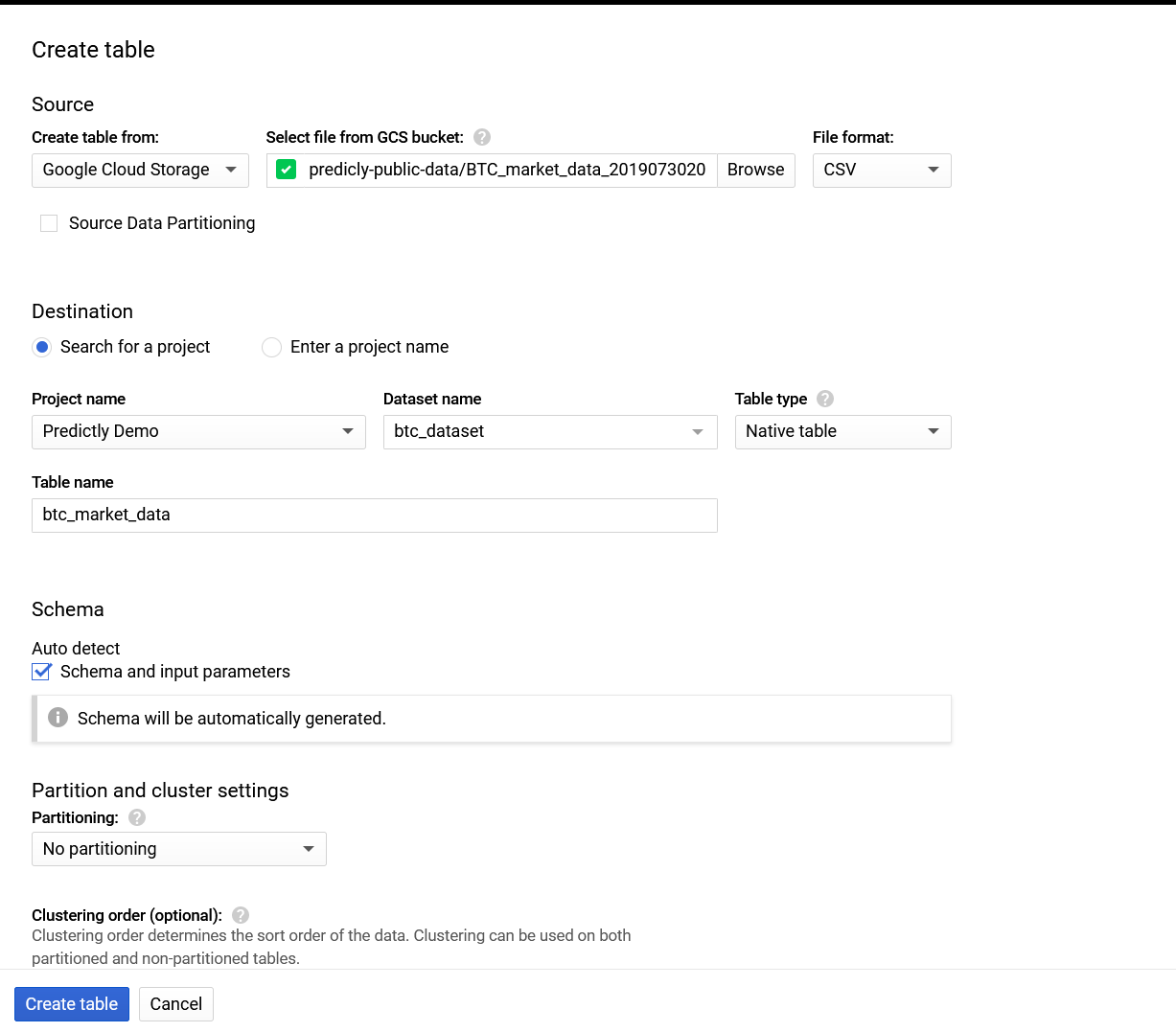
Select your bucket and file, choose the correct input format. The file we use for this demo has a header so BigQuery can auto detect the schema. Should you want to, you can enter it on your own.
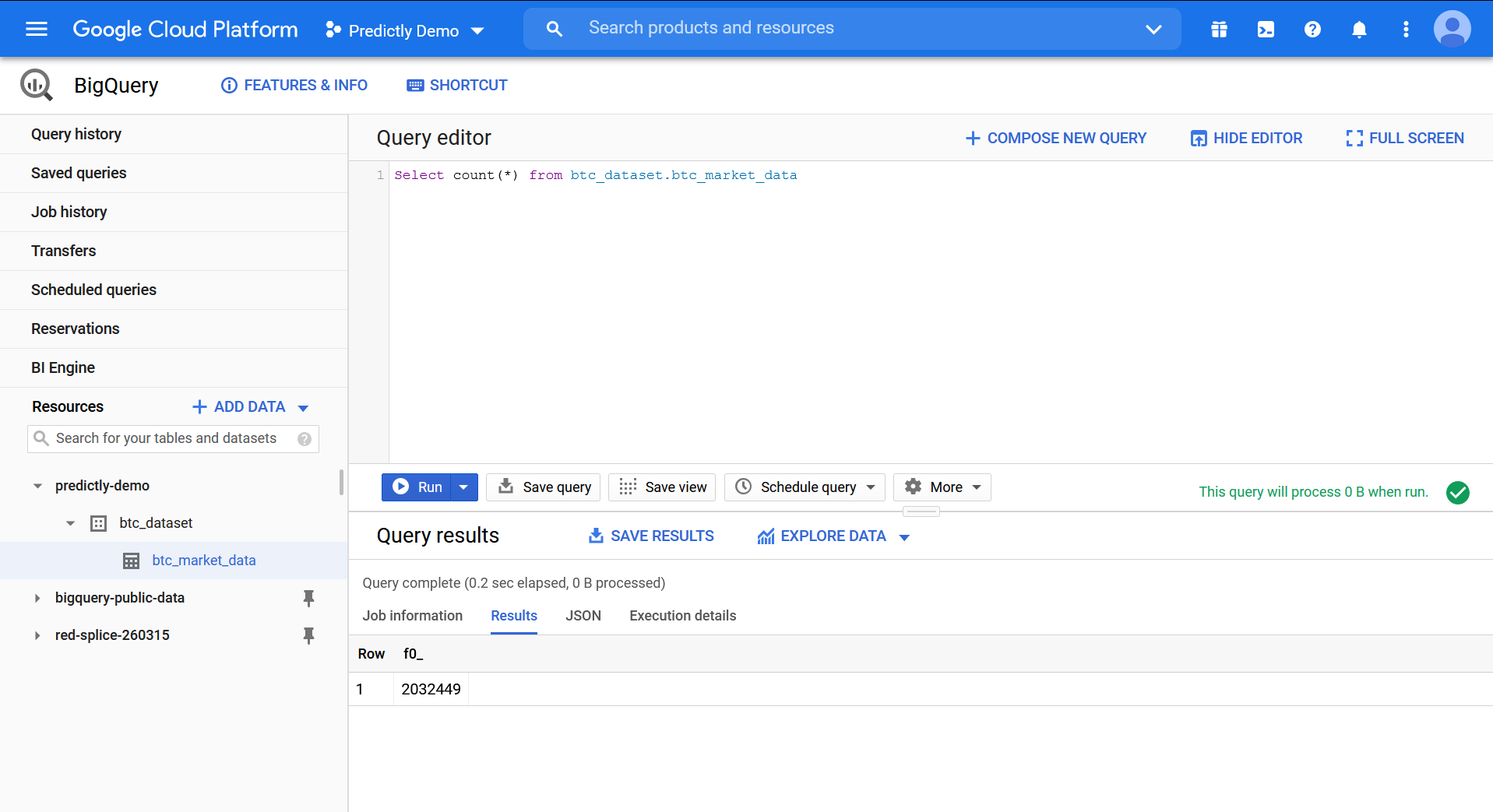
After a few minutes the data will be available in the left column.
From here it is a breeze to start working with the data using standard SQL in the your browser.
You can also use Google Data studio to visualize the data, getting a quick overview.
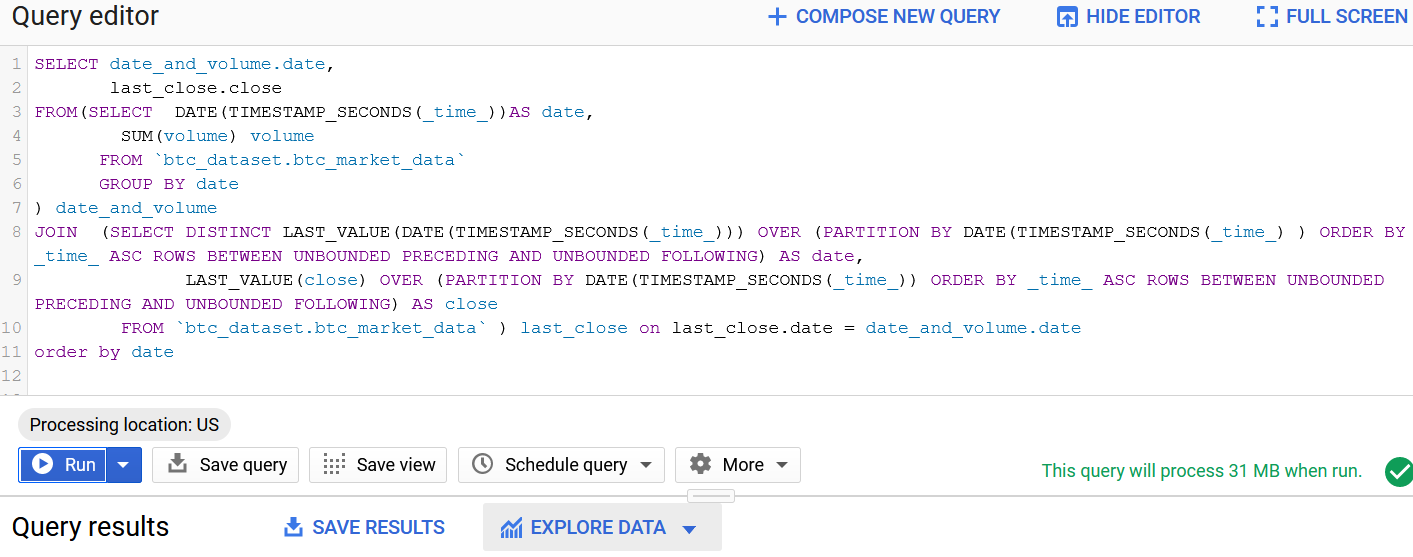
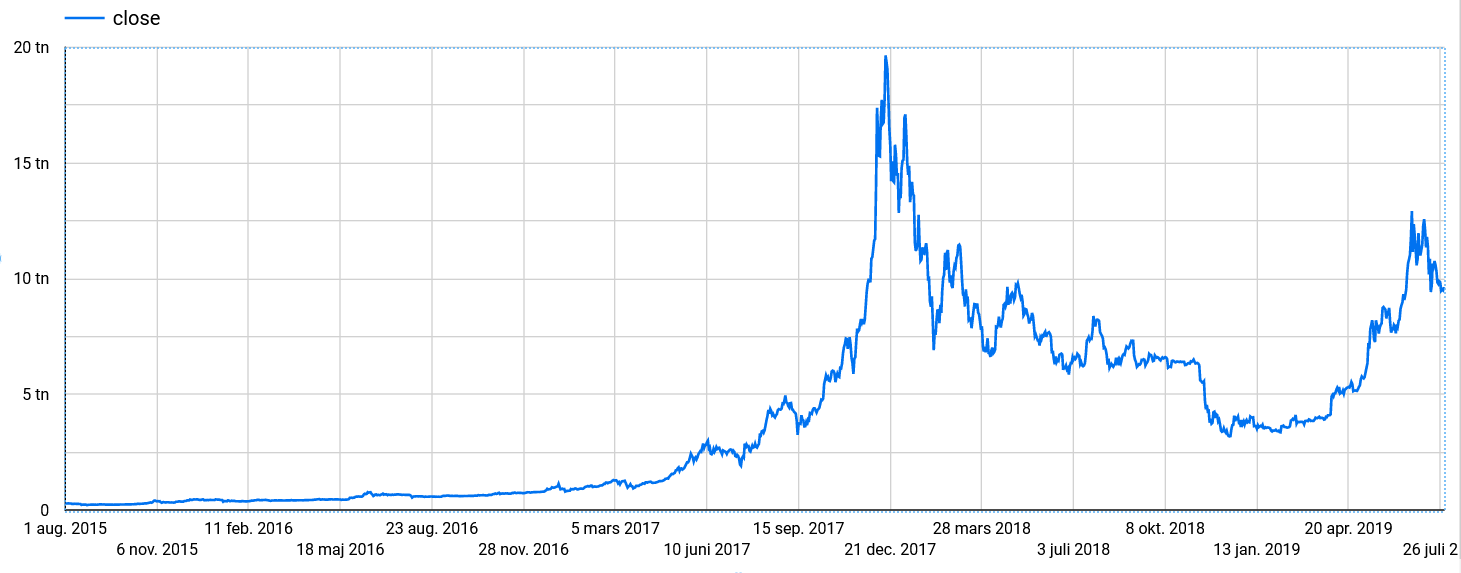
Summary
With a few simple clicks (not including actually exporting the data to a file, a story for another time) we have made data which was previously hard to access and hard to analyze, easily accessible for applications and data scientists alike.
In the next part of this series, I will talk about how we can use Googles AI platform and Jupyter notebooks to integrate with BigQuery and analyze the data further, and how to build an Apache Beam pipeline running on Google Dataflow. You can find it here.
Fler insikter och blogginlägg
När vi stöter på intressanta tekniska saker på våra äventyr så brukar vi skriva om dom. Sharing is caring!

A summary of the most interesting AI Use Cases we have implemented.

Composable commerce skapar förmågan att möta kunders ändrade förväntningar snabbt och framgångsrikt.

Data Mesh is a strategy for scaling up your reporting and analysis capabilities. Learn more about the Google Cloud building blocks that enable your Data Mesh.
