


In the last article we covered how to make our data accessible and available. Now that we have our raw data in a BigQuery table we can begin exploring and getting to know our data.
Data exploration is a highly iterative process. It helps to work in an interactive environment, where the data is kept in memory. This allows the user to make multiple transformations, visualizations and test hypothesis without needing to query the raw data multiple times.
For this purpose we are going to use a GCP hosted Jupyter Notebook, a well known tool for most data scientists.

Data exploration
The notebook allows the data scientist to use the tools already known to them, like pandas or numpy for data transformations, or seaborn and matplotlib for data visualizations.
The notebook environment also allows the data scientist to work from anywhere without having to setup a local environment, opening connections to fire walled source systems, etc., tasks that usually comes with both great headaches and long delays.
We can instead focus on enabling more and faster data innovation, since our data, setup and installation of the environment and computations are entirely managed by GCP.
To start a new notebook instance, in you cloud console, navigate to AI platform -> Notebooks and start a new notebook.
For our purposes we will use a Standard Python2 and 3 notebook with default settings.
When the instance is ready click the link to open JupyterLab.
Data exploration is an iterative process where you make multiple passes over the data, making new findings as you go. This process is hard to show in an article, so for the ones of you who are interested in how I came to the conclusions ahead, here is a gist with the notebook where I explored the data.
What i found was that the data had two main issues:
- Duplicate data
- Gaps in our timeline
For any application to provide meaningful and accurate results, issues like this needs to be addressed.
Addressing the data issues
We can use our notebook environment to quickly develop and test a Dataflow pipeline which addresses these two issues. The final step of our pipeline will load the data to a new BigQuery Table, making the clean data available for other use cases and even further reducing the barriers to more data innovation.
Dataflow is a managed service for executing a wide range of data transformations. In streams or batch. Dataflow allows us to focus on writing data transformations and not have to worry about infrastructure scaling. It also allows us to stay in the cloud for data transformation. Find out more here.
First we need a new notebook instance with Dataflow support. The notebook provides us with an interactive environment, where we can work with the real data while develop the pipeline.
In you cloud console, navigate to Dataflow -> Notebooks and start an new notebook. This notebook is based on an image which contains all the dependencies for interactive Dataflow development.
Dataflow needs to store some intermediate results somewhere, so we also need to create a new bucket in google storage for this purpose. When we have created the bucket for intermediate results, we can start building our pipeline. I called mine predictly-beam-temp.
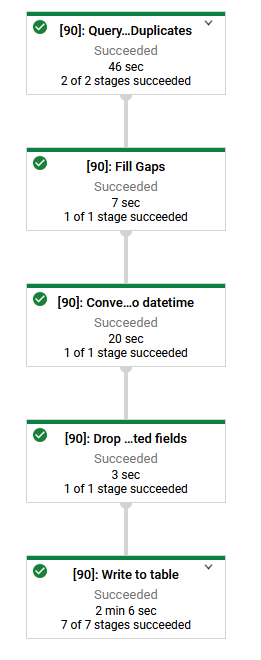
The Dataflow API available in the notebook provides us with two very useful functions. Show and Graph. The first allows us to have a look at the intermediate results of our transformations. The second draws a graph o the entire pipeline, giving us a good understanding of what we are building.
This allows us to quickly develop a pipeline which addresses the issues we identified in the previous article.
Below is a gist showing a notebook, with comments on how each issue is solved using a combination of BigQuery and Dataflow.
The last cell in the notebook starts a Dataflow job which you can view in the GCP dashboard.
Summary
In this article I have demonstrated how you can use interactive environments provided by Jupyter notebooks on GCP for data exploration and for building and testing Dataflow pipelines on GCP. This allowed us to easily explore our data and identify issues, and quickly develop a data transformation pipeline which addressed those issues. By working in this way, we made a new and clean dataset available for our next step, Modelling.
Fler insikter och blogginlägg
När vi stöter på intressanta tekniska saker på våra äventyr så brukar vi skriva om dom. Sharing is caring!

A summary of the most interesting AI Use Cases we have implemented.

Composable commerce skapar förmågan att möta kunders ändrade förväntningar snabbt och framgångsrikt.

Data Mesh is a strategy for scaling up your reporting and analysis capabilities. Learn more about the Google Cloud building blocks that enable your Data Mesh.
