


As we are starting to build transformations with Dataform, we looked into utilizing native BigQuery functionality to not only save money but also gain performance. Let me show you how.
What you are paying for
Google BigQuery is an enterprise data warehouse integrated into GCP. It provides enormous processing power while minimizing the administrative effort required by its users.
Dataform is a platform to build and manage data workflows in cloud data warehouses. It was recently acquired by Google and it’s likely that the tight integration with BigQuery will only grow stronger.
While Dataform is free of charge, BigQuery is not. Pricing is mainly based on 2 components: Storage and Analysis. There’s not much you can do about the amount of data stored but it’s quite interesting to take a closer look at how Analysis is billed and how you as a developer can work with that. (note that the following is valid for the on-demand pricing model)
How to act intelligently in BigQuery…
Ad-hoc queries are billed by the number of bytes processed by BigQuery; at the time of writing Google charges $5.00 per terabyte. Not supporting indexes, the usual way BigQuery handles growing tables is by adding compute resources to keep computing times at an acceptable level. This is a great approach for the developer as there’s no headache about the optimal indexing strategy but sooner or later the finance department might give you a call…
This is where partitioning comes into play. The technique has been known in traditional databases for over 20 years — as an example, Oracle introduced it in 1997 with version 8.0 — and is available out of the box in BigQuery as well. It means that all data is saved in “segments” or “partitions” based on a criteria. If a query filters on that criteria, vast parts of the data can be ignored rather than filtered, a technique called pruning.
Partitioning customer orders
Let’s look at an example to get a better grasp of the concept: we start with a table containing orders that’s partitioned daily on the order-ts-column. You can think of this as many small tables, each of which containing the orders of exactly one day. If you’re now looking for last weeks’ orders, BigQuery will understand that there are 7 partitions you’re interested in — and that it can ignore all others. Assuming you keep data over a period of 5 years and that the amount of orders is pretty stable over time, you just saved BigQuery scanning through 1820 days’ worth of data — or 99.6 % of all orders. Spin this thought further: you also saved 99.6 % of your money. An offer you can’t resist, right?
…and how to do the same thing in Dataform
Dataform goes its own way in some respects. For example, required columns don’t exist and you’re supposed to ensure their integrity with an assertion instead. This makes it extremely easy for anyone with basic knowledge in SQL to create transformations but it sometimes isn’t obvious how to use certain more advanced features.
And that’s the case with partitioning as it’s hidden behind the BigQuery configuration parameter which provides us with the partitionBy option. So you can define a table as follows:
config {
type: "table",
bigquery: {
partitionBy: "TIMESTAMP_TRUNC(order_ts, DAY)"
}
}
SELECT order_id, order_ts, order_no, order_reference,
payment_method, transportation_method
FROM ${ref("orders_deduplicated")}
This will partition the table on the order_ts column and create one partition per day. After executing the script it can be confirmed in the Google Cloud Console:
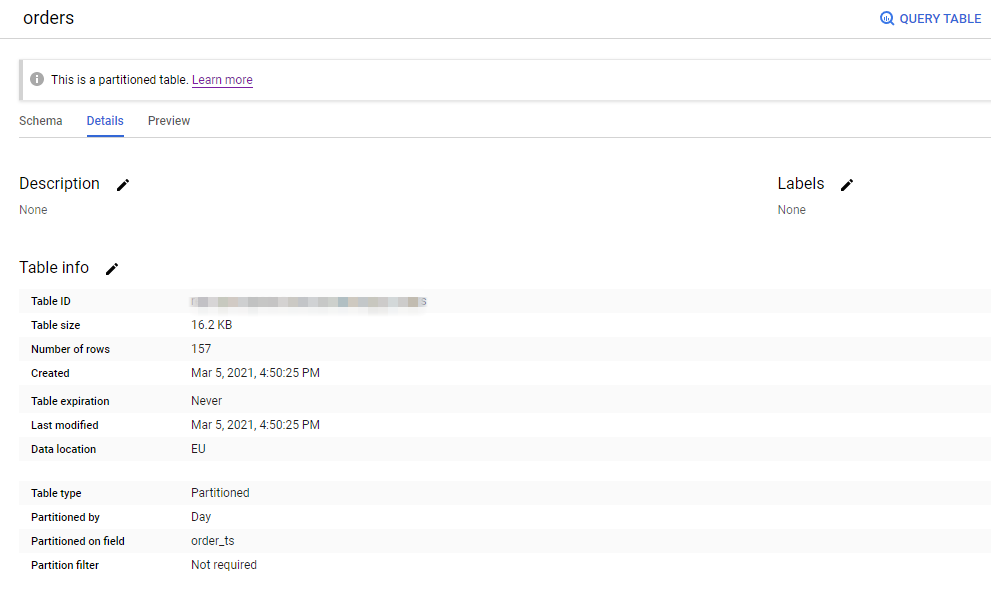
Partitioning comes without any real downside and should be considered as a standard technique in every bigger data warehouse as it both helps performance and saves money.
I hope you found this article useful. Stay tuned for more tips and tricks around BigQuery, Dataform and much more!
Fler insikter och blogginlägg
När vi stöter på intressanta tekniska saker på våra äventyr så brukar vi skriva om dom. Sharing is caring!

A summary of the most interesting AI Use Cases we have implemented.

Composable commerce skapar förmågan att möta kunders ändrade förväntningar snabbt och framgångsrikt.

Data Mesh is a strategy for scaling up your reporting and analysis capabilities. Learn more about the Google Cloud building blocks that enable your Data Mesh.
